
The Interpretation Economy Is Coming for Your Lead Funnel
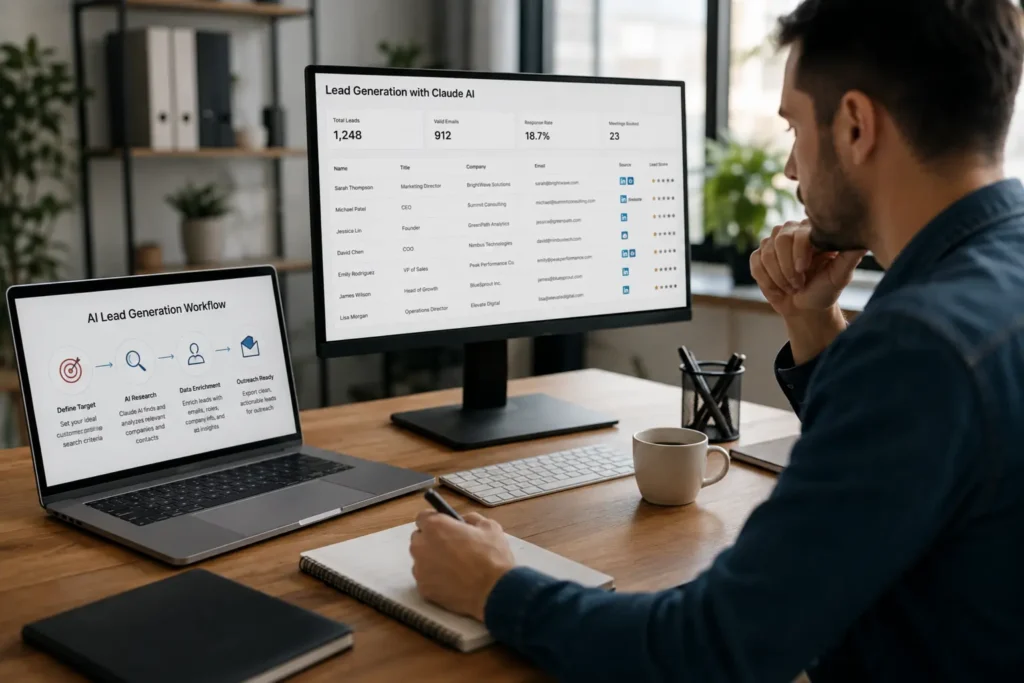
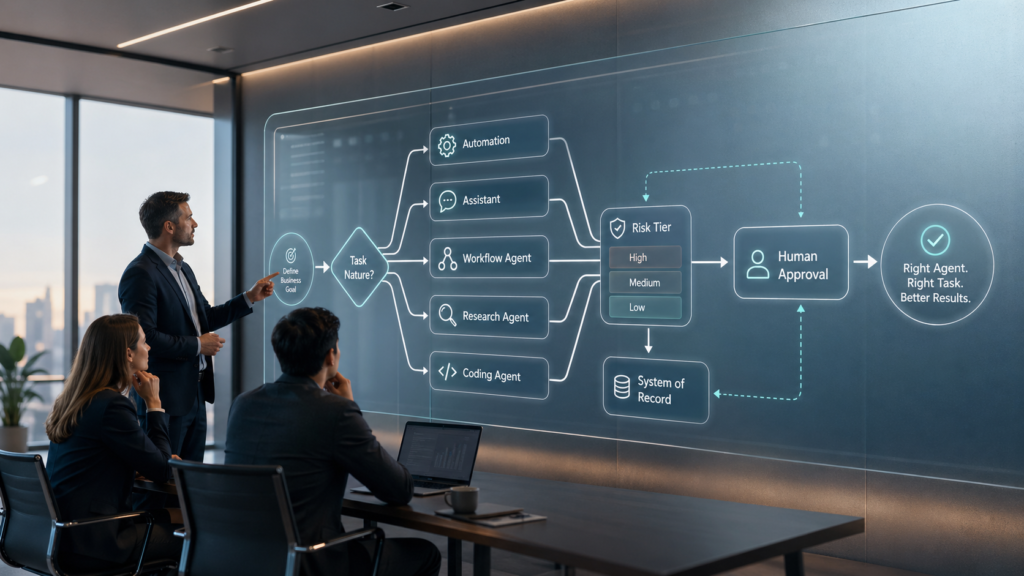
The Interpretation Economy Is Coming for Your Lead Funnel Picture Ethan. Ethan is a digital marketer running on iced coffee and the lingering delusion that he is a puppet master of the human psyche. Ethan is currently testing 120 different ad creatives a week, an absolutely stupid, unnecessary volume of A/B testing. He builds Facebook […]